
1. 과제 목표
1. 과제 목표: A 자동차 회사의 글로벌 서비스를 위한 고가용성, 확장성, 보안성을 갖춘 3-Tier 아키텍처 설계,
전 세계 사용자가 접속하는 차량 정보 플랫폼을 위한 인프라 설계
- 고가용성/확장성을 갖춘 3-Tier 아키텍처
- Redis 캐시 기반의 빠른 조회 처리
- Kafka를 통한 조회 이벤트 수집
- Druid + Superset을 활용한 운영자용 대시보드 구성
- MySQL CDC를 통한 데이터 변경 실시간 분석 (선택적 확장)
프로젝트 flow
[사용자]
↓ 요청 (ex. 차량번호 조회)
[프론트엔드]
↓ API 호출 (/vehicle/12가1234)
[백엔드 API 서버]
┌─────────────┬────────────────┐
│ Redis 캐시 │ MySQL DB │ ← 실제 차량 데이터 저장
└────┬────────┴────────┬───────┘
▼ ▼
캐시 miss → DB 조회 데이터 응답
▼
Kafka Producer로 이벤트 발행 → topic: vehicle.query.log
▼
[Kafka Broker]
▼
[Druid] → [Superset (운영자 대시보드용)]
활용 예시)
1. 사용자: 웹사이트에 접속해서 차량번호 '12가1234'를 입력
2. 프론트엔드: 이 값을 백엔드 API `/vehicle/12가1234`에 요청
3. 백엔드: 받은 요청을 다음 순서로 처리
a. Redis(캐시)에서 해당 차량 정보가 있는지 확인
b. 있으면 즉시 응답
c. 없으면 DB에서 정보 조회
d. 조회한 내용을 Redis에 저장 (캐싱)
e. **Kafka 토픽(vehicle.query.log)에 "조회 이벤트"를 발행**
f. Kafka에 {"event": "vehicle_lookup", "vehicle_id": "12가1234"} 메시지 발송
4. 응답: 사용자에게 JSON으로 차량 정보 전달
Superset을 통해 시각화하여 지금 어떤 차량이 많이 조회되고 있는지, 비정상 조회는 없는지 확인 가능
2. 카카오클라우드 환경 설계
1. 기술 구성 요약
구성요소KakaoCloud 서비스설명
| 클러스터 | KKE | 프론트/백엔드 구동 |
| 프론트엔드 | GitHub 오픈소스 | 차량 조회 UI |
| 백엔드 | FastAPI (또는 Node.js) | 차량 정보 API + Kafka Producer |
| 캐시 | MemStore (Redis) | 빠른 응답 처리용 |
| 데이터베이스 | Managed DB (MySQL) | 차량 정보 저장 |
| 메시지 큐 | Advanced Managed Kafka | 조회 이벤트 수집 |
| 로그분석 | Hadoop Eco (Druid) | Kafka → 실시간 분석 |
| 시각화 | Superset | 운영자용 대시보드 |
| 도메인 연결 | KakaoCloud DNS | 사용자 접근 URL 연결 |
| CDC 확장 | Debezium (VM 내 설치) | (선택) MySQL 변경사항 Kafka 전송 |
3. Kubernetes 클러스터 구축
1. Kubernetes 클러스터 구성 (KKE)
쿠버네티스 1.29 ver / CNI : Calico / 마스터 1개 워커 3개
2. kubeconfig 파일 다운로드 및 설정
users:
- name: ${클러스터 이름}-admin
user:
exec:
apiVersion: client.authentication.k8s.io/v1beta1
args: null
command: kic-iam-auth
env:
- name: "OS_AUTH_URL"
value: "https://iam.kakaocloud.com/identity/v3"
- name: "OS_AUTH_TYPE"
value: "v3applicationcredential"
- name: "OS_APPLICATION_CREDENTIAL_ID"
value: "${액세스 키 ID 입력}"
- name: "OS_APPLICATION_CREDENTIAL_SECRET"
value: "${보안 액세스 키 입력}"
- name: "OS_REGION_NAME"
value: "kr-central-2"
기본적으로 kubectl은 $HOME/.kube/config 파일에 저장된 정보를 통해 클러스터에 접근합니다. 설정한 kubeconfig 파일을 $HOME/.kube/config 경로에 복사
mkdir $HOME/.kube
cp ${KUBECONFIG_FILE_PATH} $HOME/.kube/config
3. 정상 연동 확인
kubectl get nodes
4. 파일스토리지 생성 및 NFS Client Provisioner 설정
1. 파일 스토리지 생성
https://docs.kakaocloud.com/service/container-pack/k8se/how-to-guides/k8se-nfs
2. Helm으로 NFS Client Provisioner 배포
helm repo add nfs-subdir-external-provisioner https://kubernetes-sigs.github.io/nfs-subdir-external-provisioner/
3. NFS Client Provisioner 설치
helm install --kubeconfig=$KUBE_CONFIG nfs-subdir-external-provisioner nfs-subdir-external-provisioner/nfs-subdir-external-provisioner --set nfs.server=[File Storage IP] --set nfs.path=[File Storage Mount Path]
4. StorageClass 확인
kubectl --kubeconfig=$KUBE_CONFIG get sc
5. PersistentVolumeClaim 생성 및 자동 프로비저닝 테스트
PVC 생성 예제 파일
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: test-claim
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Mi
6. File Storage 할당하기
kubectl --kubeconfig=$KUBE_CONFIG get pvc // PVC 확인
kubectl --kubeconfig=$KUBE_CONFIG get pv // PV 확인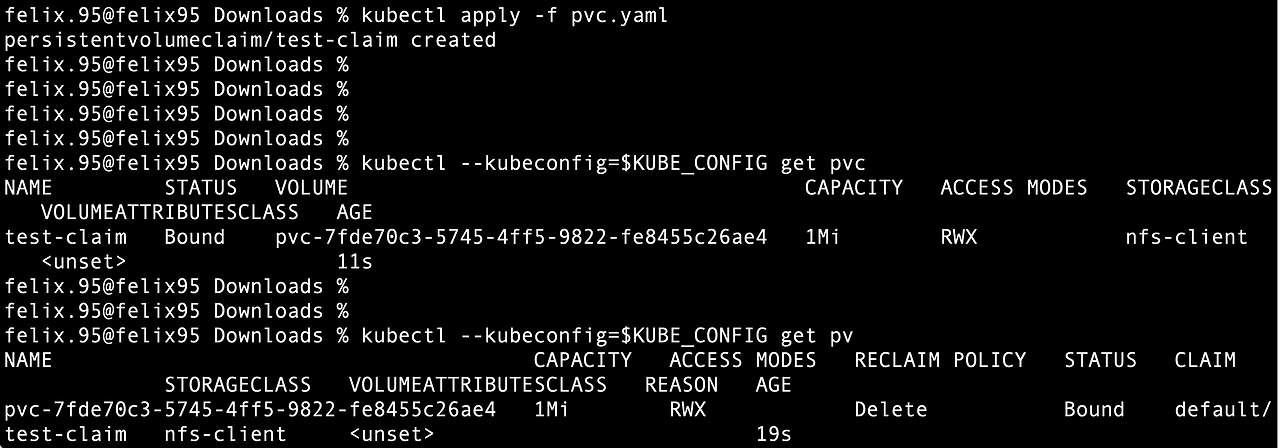
5. CR에 이미지 저장하고, 저장된 이미지로 웹 서비스 띄우기
https://docs.kakaocloud.com/tutorial/container/cr-basic
1. Container Registry 생성
| 구분 | 리포지토리 설정값 |
| 공개 여부 | 비공개 |
| 리포지토리 이름 | cr-felix-test |
| 태그 덮어쓰기 | 가능 |
| 이미지 스캔 | 자동 |
2. 예제 프로젝트 도커 이미지 빌드
예제 프로젝트를 설치할 디렉터리를 생성하고 작업 디렉터리를 생성한 디렉터리로 설정
mkdir ~/hdtest
cd ~/hdtest
예제 프로젝트를 설치
# 차량 사이트 구축 오픈소스 레포지토리 참고하여 진행하였습니다.
git clone https://github.com/Dcode36/car-management-application.git
작업 디렉터리를 예제 프로젝트 경로로 이동합니다.
예제 프로젝트 파일을 확인합니다.
ls
3. 예제 프로젝트 빌드
Docker 실행 환경 확인
docker info
서버 프로젝트를 linux/amd64 환경으로 빌드합니다.
빌드된 서버 컨테이너 이미지를 카카오클라우드 환경에 맞게 태그를 설정합니다.
클라이언트 프로젝트를 linux/amd64 환경으로 빌드합니다.
빌드된 클라이언트 컨테이너 이미지를 카카오클라우드 환경에 맞게 태그를 설정합니다.
cd backend
# 이미지 빌드
docker build -t car-management-backend:latest .
# 이미지 태깅
docker tag car-management-backend:latest techcs.kr-central-2.kcr.dev/cr-felix-test/car-management-backend:latest
# 이미지 푸시
docker push techcs.kr-central-2.kcr.dev/cr-felix-test/car-management-backend:latest
cd ../frontend
# 필요 시 build 먼저 수행
npm install
npm run build
# 이미지 빌드
docker build -t car-management-frontend:latest .
# 이미지 태깅
docker tag car-management-frontend:latest techcs.kr-central-2.kcr.dev/cr-felix-test/car-management-frontend:latest
# 이미지 푸시
docker push techcs.kr-central-2.kcr.dev/cr-felix-test/car-management-frontend:latest
4.예제 프로젝트 이미지 업로드
1. Container Registry 로그인
docker login {PROJECT_NAME}.kr-central-2.kcr.dev \
--username {ACCESS_KEY} \
--password {ACCESS_SECRET_KEY}
2. 서버 컨테이너 이미지를 업로드합니다.
클라이언트 컨테이너 이미지를 업로드합니다.
# 서버(백엔드) 이미지 업로드
docker push {PROJECT_ID}.kr-central-2.kcr.dev/{REPOSITORY_NAME}/car-management-backend:latest
# 클라이언트(프론트엔드) 이미지 업로드
docker push {PROJECT_ID}.kr-central-2.kcr.dev/{REPOSITORY_NAME}/car-management-frontend:latest
3. 업로드된 이미지는 아래 명령어를 통해 다운로드할 수 있습니다. 로컬 머신에 입력하여 이미지를 설치합니다.
서버 이미지 클라이언트 이미지 다운로드
# 서버 이미지 다운로드
docker pull {PROJECT_ID}.kr-central-2.kcr.dev/{REPOSITORY_NAME}/car-management-backend:latest
# 클라이언트 이미지 다운로드
docker pull {PROJECT_ID}.kr-central-2.kcr.dev/{REPOSITORY_NAME}/car-management-frontend:latest
4. docker images로 이미지 다운로드 확인
6. CR에 저장된 이미지로 pod 띄우기
각 파드별 볼륨 마운트는 hostpath가 아닌 nfs로 생성한 pvc로 설정해주기 위해서
마운트 패스를 hostpath가 아닌 /root로 잡아주었고, 편리한 작업을 위해서 네임스페이스는 felix로 통일
시크릿 생성
kubectl create secret docker-registry kc-cr-secret \
--docker-server=techcs.kr-central-2.kcr.dev \
--docker-username=<ACCESS_KEY> \
--docker-password=<SECRET_KEY> \
--namespace=felix
서버 배포
apiVersion: apps/v1
kind: Deployment
metadata:
name: server-deployment
namespace: felix
spec:
replicas: 2
selector:
matchLabels:
app: server
template:
metadata:
labels:
app: server
spec:
containers:
- name: server
image: {PROJECT_NAME}.kr-central-2.kcr.dev/tutorial/car-management-backend:latest
env:
- name: PROFILE
value: "local"
ports:
- containerPort: 8080
volumeMounts:
- name: root-volume
mountPath: /root
imagePullSecrets:
- name: kc-cr-secret
volumes:
- name: root-volume
hostPath:
path: /root
type: Directory
---
apiVersion: v1
kind: Service
metadata:
name: server-service
namespace: felix
spec:
type: ClusterIP
selector:
app: server
ports:
- protocol: TCP
port: 8080
targetPort: 8080
서버 service 배포
apiVersion: v1
kind: Service
metadata:
name: server-service
namespace: felix
spec:
type: ClusterIP
selector:
app: server
ports:
- protocol: TCP
port: 8080
targetPort: 8080
클라이언트 deployment 배포
apiVersion: apps/v1
kind: Deployment
metadata:
name: client-deployment
namespace: felix
spec:
replicas: 2
selector:
matchLabels:
app: client
template:
metadata:
labels:
app: client
spec:
containers:
- name: client
image: {PROJECT_NAME}.kr-central-2.kcr.dev/tutorial/car-management-backend:latest
env:
- name: SERVER_ENDPOINT
value: "http://server-service.felix.svc.cluster.local:8080"
ports:
- containerPort: 80
volumeMounts:
- name: root-volume
mountPath: /root
imagePullSecrets:
- name: kc-cr-secret
volumes:
- name: root-volume
hostPath:
path: /root
type: Directory
클라이언트 service 배포
apiVersion: v1
kind: Service
metadata:
name: client-service
namespace: felix
spec:
type: LoadBalancer
selector:
app: client
ports:
- protocol: TCP
port: 80
targetPort: 80
정상적으로 파드 생성되었는지 확인
kubectl get pods -n {네임스페이스명}
콘솔에서 로드 밸런서 설정
예제 프로젝트 클라이언트의 service를 LoadBalancer 유형으로 배포하면서, 카카오클라우드 콘솔에서 Load Balancer 서비스의 로드 밸런서 목록에도 추가된 것을 확인할 수 있습니다. 로드 밸런서 목록 > [더 보기] > 퍼블릭 IP 연결을 클릭해 외부에서 서비스에 접근할 수 있게 만들 수 있습니다.
서비스 접속 확인
브라우저에서 등록한 퍼블릭 IP로 접속하여 서비스를 확인합니다.
정상적으로 연결된 경우 자동차 차량 조회가 가능한 페이지 확인이 가능합니다.
4. Ingress Controller + DNS 설정
1. Ingress Controller 설치 (nginx)
Helm repo 추가 및 업데이트
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
helm repo update
nginx ingress controller 설치
# hostNetwork: true 설정한 커스텀 예제
helm install ingress-nginx ingress-nginx/ingress-nginx \
--set controller.hostNetwork=true \
--namespace ingress-nginx --create-namespace
# 기존 ingress-nginx Helm이 배포되어 있는 경우
helm upgrade \
--set controller.hostNetwork=true \
--namespace ingress-nginx \
ingress-nginx \
ingress-nginx/ingress-nginx
2. 설치 후 확인
Ingress Controller 설치 확인
kubectl get pods -n ingress-nginx
# Running 상태여야 정상
외부 IP 확인
kubectl get svc -n ingress-nginx
3. 인그레스 컨트롤러에 개인 도메인 연결 후 접근 확인
- 가비아를 통해 카카오클라우드 네임서버 등록

- 개인 도메인을 이용하여 DNS로 웹 서비스에 도메인 연결 진행 (KC DNS 사용 O)
- 카카오클라우드 DNS 설정

- 페이지 정상 접속 확인
5. Memstore 연동(진행중)
추후 추가 예정
6. Kafka를 통한 CDC Pipeline 구축(수정 예정)
1. VPC와 서브넷 설정
CDC 파이프라인의 각 구성 요소들이 안전하게 통신할 수 있는 격리된 네트워크 환경을 구성합니다. VPC와 서브넷을 생성하여 외부 접근으로부터 보호하고, 내부 구성 요소들 간의 원활한 통신을 가능하게 합니다.
- 카카오클라우드 콘솔 > Beyond Networking Service > VPC 메뉴로 이동합니다.
- 우측의 [VPC 생성] 버튼을 클릭하여 새로운 VPC를 생성합니다.VPC: tutorial-cdc-vpc
- 하단의 [생성] 버튼을 클릭합니다.
2. 보안 그룹 설정
CDC 파이프라인의 보안을 위해 네트워크 접근 정책을 구성합니다. 내부적으로는 MySQL, Advanced Managed Kafka, Hadoop Eco 구성요소들 간의 안전한 통신을 허용하고, 외부에서는 관리 목적으로 특정 IP에서만 접근 가능하도록 제한하는 보안 그룹을 설정합니다.
- 카카오클라우드 콘솔 > Beyond Networking Service > VPC 메뉴에서 보안 그룹을 선택합니다.
- [보안 그룹 생성] 버튼을 클릭하여 새 보안 그룹 생성합니다.
- 아래와 같이 보안 그룹을 구성합니다.항목설정값
이름 tutorial-cdc-sg 설명 CDC Pipeline 보안 정책 - 인바운드 규칙을 다음과 같이 구성합니다. 먼저 사용자의 Public IP에 대한 접근을 허용합니다.항목설정값비고
프로토콜 ALL 모든 프로토콜 허용 출발지 {사용자 퍼블릭 IP}/32 포트 번호 ALL 정책 설명(선택) Allow Access from User Public IP -
나의 퍼블릭 IP 확인하기
다음 버튼을 클릭하면 현재 사용 중인 나의 퍼블릭 IP를 확인할 수 있습니다.
나의 퍼블릭 IP 확인하기 - 보안 그룹 생성 후, 보안 그룹 상세 페이지에서 인바운드 규칙 관리 버튼 클릭 후 다음 인바운드 규칙을 구성합니다.항목설정값비고
프로토콜 ALL 모든 프로토콜 허용 출발지 @tutorial-cdc-sg 동일 보안 그룹 내부 통신 허용 포트 번호 ALL 정책 설명(선택) Internal SG Access
3. MySQL 인스턴스 그룹 생성
CDC 파이프라인이 추적할 원본 데이터베이스를 설정합니다. 여기서는 사용자 정보를 관리하는 테이블을 생성하고, Debezium이 변경 사항을 감지할 수 있도록 필요한 데이터베이스 설정을 구성합니다. 생성된 테이블에서 발생하는 모든 데이터 생성(INSERT), 수정(UPDATE), 삭제(DELETE) 작업이 실시간으로 감지되어 파이프라인으로 전달됩니다.
- 카카오클라우드 콘솔 > Data Store > MySQL > Instance Group 메뉴로 이동합니다.
- [인스턴스 그룹 생성] 버튼을 클릭하여 새로운 MySQL 인스턴스를 생성합니다. 아래에서 언급되지 않은 설정은 기본값을 유지합니다.항목설정값
인스턴스 그룹 이름 tutorial-cdc-mysql 인스턴스 가용성 단일 MySQL 사용자 이름 admin MySQL 비밀번호 admin123 VPC tutorial-cdc-vpc Subnet main 자동 백업 옵션 사용
4. Debezium Connector 설치를 위한 VM 생성
MySQL의 데이터 변경사항을 감지하고 Kafka로 전송하는 Debezium Connector를 실행하기 위한 VM 환경을 구성합니다.
키 페어 설정
- 카카오클라우드 콘솔 > Beyond Compute Service > Virtual Machine > 키 페어 메뉴로 이동합니다.
- [키 페어 생성] 버튼을 클릭하여 새로운 키 페어를 생성합니다.
- 이름: tutorial-cdc-keypair
주의생성된 키 페어(.pem 파일)는 최초 1회만 다운로드 가능하며, 안전한 곳에 보관해야 합니다. 잃어버린 키는 복구할 수 없으며, 재발급이 필요합니다.
VM 인스턴스 생성
- 카카오클라우드 콘솔 > Beyond Compute Service > Virtual Machine > 인스턴스 메뉴로 이동합니다.
- [인스턴스 생성] 버튼을 클릭하여 다음과 같이 VM을 생성합니다. 아래에서 언급되지 않은 설정은 기본값을 유지합니다.구분항목설정값비고
기본 정보 이름 tutorial-cdc-vm 이미지 OS Ubuntu 22.04 인스턴스 유형 t1i.small 볼륨 루트 볼륨 30 GB SSD 키 페어 tutorial-cdc-keypair 네트워크 VPC tutorial-cdc-vpc 보안 그룹 tutorial-cdc-sg 서브넷 main
5. Advanced Managed Kafka 클러스터 생성
CDC를 통해 포착된 데이터 변경사항을 실시간으로 스트리밍하고 다른 시스템으로 전달하기 위한 Advanced Managed Kafka 클러스터를 구성합니다.
- 카카오클라우드 콘솔 > Analytics > Advanced Managed Kafka > 클러스터 메뉴로 이동합니다.
- [클러스터 생성] 버튼을 클릭한 후, 다음과 같이 클러스터를 생성합니다. 아래에서 언급되지 않은 설정은 기본값을 유지합니다.구분항목설정값비고
기본 설정 클러스터 이름 tutorial-cdc-kafka 인스턴스 유형 r2a.2xlarge 네트워크 VPC tutorial-cdc-vpc 서브넷 main, {VPC_ID}_sn_1 (10.0.16.0/20) 보안 그룹 tutorial-cdc-sg 브로커 구성 브로커 수 2 가용 영역당 1개씩 배포
6. Hadoop Eco 클러스터 생성
Kafka로부터 전달받은 데이터 변경사항을 저장하고 분석하기 위한 Druid와, 이를 시각화하기 위한 Superset을 포함한 분석 환경을 구성하기 위해 Hadoop Eco Dataflow 유형 클러스터를 생성합니다.
- 카카오클라우드 콘솔 > Analytics > Hadoop Eco > 클러스터 메뉴로 이동합니다.
- [클러스터 생성] 버튼을 클릭하여 다음과 같이 클러스터를 생성합니다.1단계: 클러스터 설정구분항목설정값
2단계: 인스턴스 설정구분항목설정값기본 정보 클러스터 이름 tutorial-cdc-dataflow 클러스터 구성 클러스터 유형 Dataflow 관리자 설정 관리자 아이디 admin 관리자 비밀번호 Admin123! (대문자 유의) VPC 설정 VPC tutorial-cdc-vpc 서브넷 main 보안 그룹 구성 기존에 생성된 보안 그룹 중에 선택 보안 그룹 이름 tutorial-cdc-sg
3단계: 상세 설정상세 설정은 변경하지 않고 생성 버튼을 눌러 Hadoop Eco Dataflow 유형 클러스터를 생성합니다.마스터 노드 설정 마스터 노드 인스턴스 타입 m2a.xlarge 워커 노드 설정 워커 노드 인스턴스 타입 m2a.xlarge 키 페어 tutorial-cdc-keypair
시작하기
Step 1. 퍼블릭 IP 설정
CDC 파이프라인 구성을 위해서는 VM 인스턴스와 Hadoop Eco 클러스터에 외부에서 접근할 수 있어야 합니다. 이를 위해 각 인스턴스에 퍼블릭 IP를 부여하고, 이후 SSH 접속 및 웹 인터페이스 접근에 사용합니다.
VM 인스턴스 Public IP 할당
- 카카오클라우드 콘솔 > Virtual Machine 메뉴로 이동합니다.
- 인스턴스 탭에서 tutorial-cdc-vm 인스턴스 이름을 클릭합니다.
- 우측의 [인스턴스 작업] 버튼을 클릭 후 [퍼블릭 IP 연결] 버튼을 클릭합니다.
- 퍼블릭 IP 연결 창에서 별도 수정 없이 [확인] 버튼을 클릭합니다.
Hadoop Eco Master Node Public IP 할당
- 카카오클라우드 콘솔 > Virtual Machine 메뉴로 이동합니다.
- 인스턴스 탭에서 HadoopMST-tutorial-cdc-dataflow-1 인스턴스 이름을 클릭합니다.
- 우측의 [인스턴스 작업] 버튼을 클릭 후 [퍼블릭 IP 연결] 버튼을 클릭합니다.
- 퍼블릭 IP 연결 창에서 별도 수정 없이 [확인] 버튼을 클릭합니다.
연결된 퍼블릭 IP는 인스턴스 목록 또는 인스턴스 이름을 클릭하여 이동한 인스턴스 상세 페이지의 네트워크 탭에서 확인할 수 있습니다.
Step 2. Debezium 서버 환경 구성
CDC 파이프라인 구성에 필요한 기본 소프트웨어와 도구들을 설치하고 환경을 구성합니다. Java, MySQL Client, Kafka 등 필수 구성요소들을 설정합니다.
- 로컬 환경의 터미널에서 키 페어 파일이 있는 디렉터리로 이동합니다.
-
cd ~/Downloads # 또는 키 페어 파일이 저장된 디렉터리 - 키 페어 파일의 권한을 설정합니다.
-
sudo chmod 400 tutorial-cdc-keypair.pem - SSH를 통해 VM에 접속합니다.
-
환경변수설명
ssh -i tutorial-cdc-keypair.pem ubuntu@${VM_PUBLIC_IP}VM_PUBLIC_IP🖌︎ VM 인스턴스 > 네트워크 탭에서 확인 가능한 퍼블릭 IP - Java 실행 환경을 설치하고 환경 변수를 구성합니다.
-
sudo apt update sudo apt install -y openjdk-21-jdk # Java 환경변수 설정 cat << EOF | sudo tee -a /etc/profile export JAVA_HOME=/usr/lib/jvm/java-21-openjdk-amd64 export PATH=\$JAVA_HOME/bin:\$PATH export CLASSPATH=\$CLASSPATH:\$JAVA_HOME/lib/ext:\$JAVA_HOME/lib/tools.jar EOF source /etc/profile - MySQL 데이터베이스 관리를 위한 클라이언트 도구를 설치합니다.
-
sudo apt install -y mysql-client - Kafka 클러스터를 관리하기 위한 도구를 설치합니다. Kafka 도구는 클러스터와 동일한 버전으로 설치해야 합니다. 본 튜토리얼에서는 3.7.1 버전을 사용합니다.
cd ~ curl https://archive.apache.org/dist/kafka/3.7.1/kafka_2.13-3.7.1.tgz -o kafka_2.13-3.7.1.tgz tar -xzf kafka_2.13-3.7.1.tgz rm kafka_2.13-3.7.1.tgz mv kafka_2.13-3.7.1 kafka -
정보
Kafka 버전별 다운로드는 https://archive.apache.org/dist/kafka/ 에서 확인할 수 있습니다.
Step 3. Debezium 설정
Debezium은 MySQL의 바이너리 로그를 읽어 데이터 변경사항을 감지하는 CDC 도구입니다. 이 단계에서는 Debezium을 설치하고, MySQL의 변경사항을 Kafka로 전송할 수 있도록 구성합니다. 이를 통해 데이터베이스의 모든 변경사항을 실시간으로 포착할 수 있게 됩니다.
- Debezium MySQL 커넥터 플러그인을 다운로드하고 설치합니다.
-
mkdir -p ~/kafka/plugins wget https://repo1.maven.org/maven2/io/debezium/debezium-connector-mysql/3.0.2.Final/debezium-connector-mysql-3.0.2.Final-plugin.tar.gz tar -xzf debezium-connector-mysql-3.0.2.Final-plugin.tar.gz -C ~/kafka/plugins/ rm debezium-connector-mysql-3.0.2.Final-plugin.tar.gz - Kafka Connect 분산 모드 설정을 구성합니다.
-
환경변수설명
cat << EOF > /home/ubuntu/kafka/config/connect-distributed.properties bootstrap.servers=${KAFKA_BOOTSTRAP_SERVERS} group.id=connect-cluster key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable=false value.converter.schemas.enable=false plugin.path=/home/ubuntu/kafka/plugins offset.storage.topic=connect-offsets offset.storage.replication.factor=1 config.storage.topic=connect-configs config.storage.replication.factor=1 status.storage.topic=connect-statuses status.storage.replication.factor=1 auto.create.topics.enable=true EOFKAFKA_BOOTSTRAP_SERVERS🖌︎ Advanced Managed Kafka > 클러스터의 부트스트랩 서버 주소 - 시스템 서비스로 등록하여 항상 실행되도록 설정합니다.
-
sudo sh -c 'cat << EOF > /etc/systemd/system/kafka-connect.service [Unit] Description=Kafka Connect Distributed Documentation=http://kafka.apache.org/ After=network.target kafka.service [Service] Type=simple User=ubuntu Environment="KAFKA_HEAP_OPTS=-Xms128M -Xmx512M" ExecStart=/home/ubuntu/kafka/bin/connect-distributed.sh /home/ubuntu/kafka/config/connect-distributed.properties Restart=always RestartSec=10 [Install] WantedBy=multi-user.target EOF' sudo systemctl daemon-reload sudo systemctl start kafka-connect sudo systemctl enable kafka-connect - 다음 명령어를 실행하여 kafka-connect 서비스가 running 상태인지 확인합니다. 상태 확인 후 Ctrl + C를 눌러 종료합니다.
-
sudo systemctl status kafka-connect
Step 4. MySQL 데이터베이스 설정
CDC의 소스가 되는 MySQL 데이터베이스와 테이블을 생성하고 초기 데이터를 설정합니다. 이는 데이터 변경사항을 추적할 기반 환경을 구성하는 단계입니다.
- MySQL 서버에 원격으로 접속합니다.
-
환경변수설명
mysql -h ${MYSQL_ENDPOINT} -u admin --password=admin123MYSQL_ENDPOINT🖌︎ MySQL 인스턴스의 엔드포인트 - CDC 테스트를 위한 데이터베이스와 테이블을 생성합니다.
-
CREATE DATABASE `cdc-database`; USE `cdc-database`; CREATE TABLE `cdc-table` ( id BIGINT NOT NULL AUTO_INCREMENT, name VARCHAR(100), email VARCHAR(200), status ENUM('active', 'inactive') DEFAULT 'active', created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (id) ); - MySQL 접속을 종료하려면 다음 명령어를 입력합니다.
-
exit
Step 5. Debezium Connector 구성 및 MySQL 테스트 데이터 생성
MySQL의 변경사항을 감지하고 Kafka로 전송하기 위한 Debezium 커넥터를 상세 설정합니다. 이를 통해 데이터 변경사항의 실시간 캡처가 가능해집니다.
- 커넥터 설정 파일을 생성하고 필요한 파라미터를 구성합니다.
환경변수설명
sudo tee /home/ubuntu/kafka/config/connectors/mysql-connector.json << 'EOF' { "name": "mysql-connector", "config": { "connector.class": "io.debezium.connector.mysql.MySqlConnector", "tasks.max": "1", "database.hostname": "${MYSQL_ENDPOINT}", "database.port": "3306", "database.user": "admin", "database.password": "admin123", "database.server.id": "1", "topic.prefix": "mysql-server", "database.include.list": "cdc-database", "table.include.list": "cdc-database.cdc-table", "schema.history.internal.kafka.bootstrap.servers": "${KAFKA_BOOTSTRAP_SERVERS}", "schema.history.internal.kafka.topic": "schema-changes.mysql", "topic.creation.enable": "true", "topic.creation.default.replication.factor": "1", "topic.creation.default.partitions": "1", "tombstones.on.delete": "true" } } EOFMYSQL_ENDPOINT🖌︎ MySQL 인스턴스의 엔드포인트 KAFKA_BOOTSTRAP_SERVERS🖌︎ Kafka 클러스터의 부트스트랩 서버 주소 -
sudo mkdir -p /home/ubuntu/kafka/config/connectors - REST API를 통해 커넥터를 생성합니다.
-
curl -X POST -H "Content-Type: application/json" \ --data @/home/ubuntu/kafka/config/connectors/mysql-connector.json \ http://localhost:8083/connectors - mysql-connector의 상태를 확인하기 위해 다음 명령어를 실행합니다.커넥터가 정상적으로 동작 중이면 "state": "RUNNING" 상태가 표시됩니다.
-
curl -X GET http://localhost:8083/connectors/mysql-connector/status - mysql-connector이 정상 동작할 경우, MySQL 서버에 원격으로 접속합니다.
-
환경변수설명
mysql -h ${MYSQL_ENDPOINT} -u admin --password=admin123MYSQL_ENDPOINT🖌︎ MySQL 인스턴스의 엔드포인트 - kafka 토픽 생성 및 테스트 데이터 생성을 위해 다음 쿼리를 실행합니다.
-
USE `cdc-database`; INSERT INTO `cdc-table` (name, email) VALUES ('John Doe', 'john.doe@example.com'), ('Jane Smith', 'jane.smith@example.com'), ('Bob Johnson', 'bob.johnson@example.com'), ('Alice Brown', 'alice.brown@example.com'), ('Charlie Wilson', 'charlie.wilson@example.com'); - MySQL 접속을 종료하려면 다음 명령어를 입력합니다.
-
exit
Step 6. Druid 연동 및 MySQL 쿼리 실행
Kafka로 전송된 데이터 변경사항을 실시간으로 저장하고 분석하기 위해 Druid를 구성합니다. 이를 통해 데이터의 실시간 처리와 분석이 가능해집니다.
- Hadoop Eco > Cluster > tutorial-cdc-dataflow > [Druid URL]을 통해 Druid에 접속합니다.
-
환경변수설명
http://${MASTER_NODE_PUBLIC_IP}:3008MASTER_NODE_PUBLIC_IP🖌︎ Hadoop Eco 마스터 노드의 퍼블릭 IP - 메인 화면 상단의 Load Data > Streaming 버튼을 클릭합니다. 우측 상단의 [Edit Spec] 버튼을 클릭합니다.
- 아래 JSON의 bootstarp.servers에 Kafka 클러스터의 부트스트랩 서버 주소를 붙여 넣은 뒤 [Submit] 버튼을 클릭합니다.
-
환경변수설명
{ "type": "kafka", "dataSchema": { "dataSource": "user_changes", "timestampSpec": { "column": "created_at", "format": "iso" }, "dimensionsSpec": { "dimensions": [ "id", "name", "email", "status", "operation_type", "updated_at", { "name": "__deleted", "type": "boolean" } ] }, "granularitySpec": { "type": "uniform", "segmentGranularity": "DAY", "queryGranularity": "MINUTE", "rollup": false } }, "tuningConfig": { "type": "kafka", "maxRowsPerSegment": 5000000, "maxBytesInMemory": 25000000 }, "ioConfig": { "topic": "mysql-server.cdc-database.cdc-table", "consumerProperties": { "bootstrap.servers": "${KAFKA_BOOTSTRAP_SERVERS}", "group.id": "druid-user-changes" }, "taskCount": 1, "replicas": 1, "taskDuration": "PT1H", "completionTimeout": "PT20M", "inputFormat": { "type": "json", "flattenSpec": { "useFieldDiscovery": false, "fields": [ { "type": "jq", "name": "id", "expr": ".before.id // .after.id" }, { "type": "jq", "name": "name", "expr": ".before.name // .after.name" }, { "type": "jq", "name": "email", "expr": ".before.email // .after.email" }, { "type": "jq", "name": "status", "expr": ".before.status // .after.status" }, { "type": "jq", "name": "created_at", "expr": ".before.created_at // .after.created_at" }, { "type": "jq", "name": "updated_at", "expr": ".before.updated_at // .after.updated_at" }, { "type": "jq", "name": "operation_type", "expr": ".op" }, { "type": "jq", "name": "__deleted", "expr": ".op == \"d\"" } ] } } } }KAFKA_BOOTSTRAP_SERVERS🖌︎ Kafka 클러스터의 부트스트랩 서버 주소 - Druid 콘솔의 Ingestion 탭에서 Supervisors > Datasource > user_changes > Status 가 RUNNING인지 확인합니다.
- MySQL 서버에 접속하여 데이터를 발생시키고 Druid가 데이터 변경사항을 수집할 수 있도록 합니다.
-
환경변수설명
mysql -h ${MYSQL_ENDPOINT} -u admin --password=admin123MYSQL_ENDPOINT🖌︎ MySQL 인스턴스의 엔드포인트 - 다음 쿼리를 실행하여 Druid가 데이터 변경사항을 정상적으로 수집하는지 테스트합니다.
-
USE `cdc-database`; UPDATE `cdc-table` SET status = 'inactive' WHERE id IN (2, 4); INSERT INTO `cdc-table` (name, email) VALUES ('David Park', 'david.park@example.com'); DELETE FROM `cdc-table` WHERE id = 3; - MySQL 접속을 종료하려면 다음 명령어를 입력합니다.
-
exit - Druid 콘솔의 Datasources 탭에서 새로 생성된 user_changes Datasource를 확인합니다.
Step 7. Superset 연동
수집된 데이터를 시각화하고 모니터링하기 위한 Superset 대시보드를 구성합니다. 이를 통해 데이터 변경사항을 직관적으로 파악하고 분석할 수 있습니다.
- Hadoop Eco 클러스터 > 클러스터 정보 > [Superset URL]을 통해 Superset에 접속합니다. 클러스터 생성 시 입력했던 관리자 ID, 비밀번호를 이용하여 로그인합니다.
-
환경변수설명
http://${MASTER_NODE_PUBLIC_IP}:4000MASTER_NODE_PUBLIC_IP🖌︎ Hadoop Eco 마스터 노드의 퍼블릭 IP - 상단 메뉴의 [Datasets] 버튼을 클릭합니다. 이후 Druid에서 데이터셋을 가져오기 위해 우측 상단의 [+ DATASET] 버튼을 클릭합니다.
- 아래와 같이 데이터베이스와 스키마를 설정합니다. 이후 [CREATE DATASET AND CREATE CHART] 버튼을 클릭합니다.항목설정값
DATABASE druid SCHEMA druid TABLE user_changes - 원하는 차트들을 선택하고 [CREATE NEW CHART] 버튼을 클릭합니다.
- 확인하고 싶은 데이터와 설정값들을 입력하고 [CREATE CHART] 버튼을 클릭하여 차트를 생성하고, 우측 상단의 [SAVE] 버튼을 클릭하여 차트를 저장합니다.
'카카오클라우드' 카테고리의 다른 글
| 카카오클라우드 쿠버네티스 인그레스 컨트롤러 배포 및 DNS 서비스 활용 (0) | 2025.06.30 |
|---|---|
| 카카오클라우드 OpenStack 구성을 이용한 Project Resource Quota 확인 (0) | 2025.05.30 |
| 카카오클라우드 미니 프로젝트 3(오프라인 쿠버네티스 클러스터 구축) (0) | 2025.05.03 |
| 카카오클라우드 미니 프로젝트 2(쿠버네티스 CI CD 구축하기/ Github Action, argo) (0) | 2025.04.20 |
| 카카오클라우드 미니 프로젝트 1(쿠버네티스 PVC, HPA 설정 및 부하 테스트) (0) | 2025.04.11 |